Node Js And Binary Data
UPDATE: None of this should be necessary, as FileReadStream in the latest node uses buffers by default. However, it appears that either I’m doing something wrong or the docs are out of date, as it doesn’t work that way on node HEAD.
Two areas where the exclenned Node.js’s sadly lacks is the handling of binary data and large strings. In this post I’d like to go over some techniques for dealing with binary data in node, most of which revolves around dealing with V8’s garbage collector, and the fact that strings in node are not made for binary data, they’re made for UTF-8 and UTF-16 data.
There are three main gory details that make working with data in Node.js a pain:
Large Strings (> ~64K) are not your friend. Binary (and ASCII) data in a node string are stored as the first byte of a UTF-16 string. Binary data can be most efficiently stored in Node.js as a Buffer Lets look at the first item, big strings aren’t your friend. Node.js creator ry himself tackled this issue himself in a performance comparison he made with nginx. If you view the pdf, (or look at the extracted chart below) you’ll see that node does a decent job keeping pace with nginx up until the 64 byte mark hits, then performance just falls apart. The reason, in ry’s words:
V8 has a generational garbage collector [which] moves objects around randomly. Node can’t get a pointer to raw string data to write to socket.
You can see this in the relevant graph in ryan’s slides, which I’ve conveniently extracted and posted below (I hope you don’t mind Ryan).
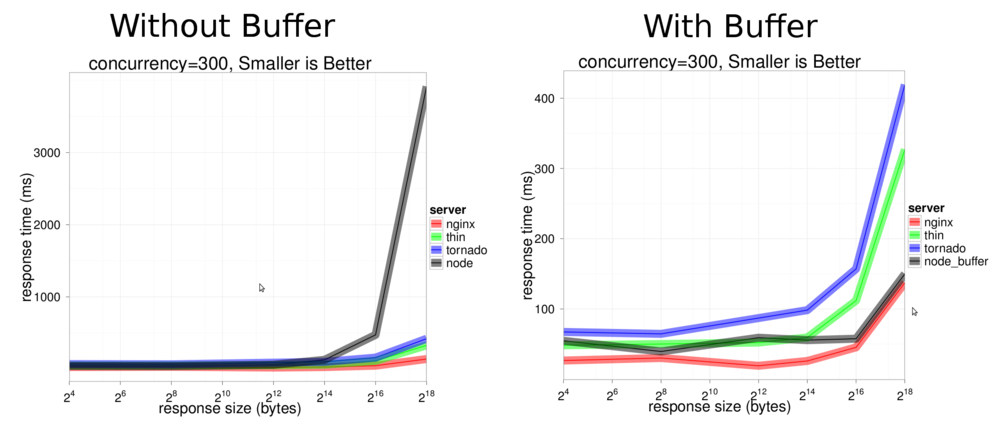
What wasn’t immediately obvious to me after reading this was what this meant in cases where one was using node to pass around large bits of binary data that come in as strings. if you use node to say, read from the file system you get back a binary string, not a buffer. My question was: “If I have binary data already stuck in a lousy UTF-16 string, but then stick it in buffer before sending it out, will that help with speed?.” The answer an increase in throughput from 100 MiB/Sec to 160 MiB/Sec.
Check out the graph below from my own performance tests, where I played with different readChunk sizes (how much data the FileReadStream reads at once and buffer sizes (How much data we store in a buffer before flushing to a socket):
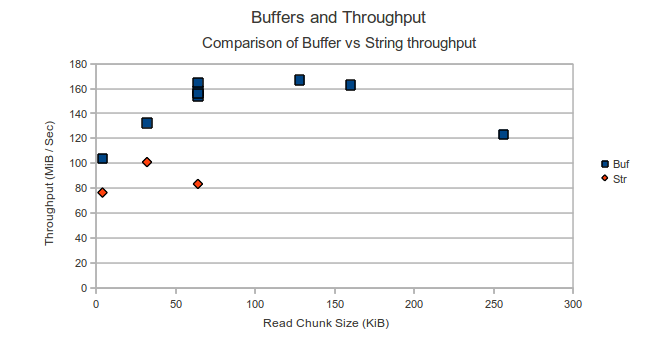
As you can see performance using buffers (Buf) beats the pants off writes using strings (Str). The difference between the two pieces of code can be seen below. I initially didn’t think that doing this conversion would help at all, I figured once it was already in a string (as data from a FileReadStream is), one may as well flush it to the socket and continue on. This makes me wonder if other apps would also be best off accumulating their output (perhaps even their UTF-8 output) in a Buffer where possible, then finally flushing the Buffer, instead of making repeat calls to res.write. Someone needs to test this. Additionally, this makes me wonder if further improvements to my own test case could be improved if the node FileReadStream object was modified to return a Buffer rather than a string.
Additionaly, you may be asking about using a larger bufSize than readChunk size, which I did indeed test, but found there was not much of a difference when using a larger buffer, so the optimal strategy really does seem to be reading a 64KiB chunk into a 64KiB buffer. You can see this data at the bottom of the post.
In the data I graphed above, I made a number of runs with ab -c 100 -n 1000 against 1 MiB file changing the chunkSize and readSize. Relevant sample code can be seen below. The full sample code would be my fork of node-paperboy.