Using Markov chains for HTTP benchmarking
In the latest version of engulf, my distributed HTTP benchmarker, I decided to support request pattern generation via Markov chains. The idea for this came from my brilliant friend Trent Strong.
When it comes to load testing your app there are a number of options available. Most load testers ship with a variety of options such as testing a single URL, testing a list of URLs, and replaying browsing sessions. Some are even fully scriptable, but we’ll leave these aside for now. Markov chains possess some qualities that these do not, such as:
- having more natural transitions than random URL selections
- generating a large number of different requests patterns from a small corpus vs. log replay
- being extremely fast to generate when compared to custom scripts
- being fuzzy yet having very similar properties to a source corpus
- in effect being a very concise DSL for request patterns
What is a Markov chain?
Markov chains are perhaps most famous for their use with natural language. Given a corpus of text a Markov generator can create a completely original piece of similar text without knowledge of the text’s natural language. It does this by analyzing patterns in the original text, and copying them with modifications. In other words a Markov chain generator can mimic language by copying patterns.
The heuristic used by a Markov chain generator is very simple. The generator simply looks at which words typically follow other words and what the probability of them following the previous word is. For example take the following corpus:
I like cheese. I like butter. I don't like ham.
The Markov chain generator might generate the following sentences:
I like butter. I like ham. I don't like cheese.
Internally, the markov chain is represented thusly:
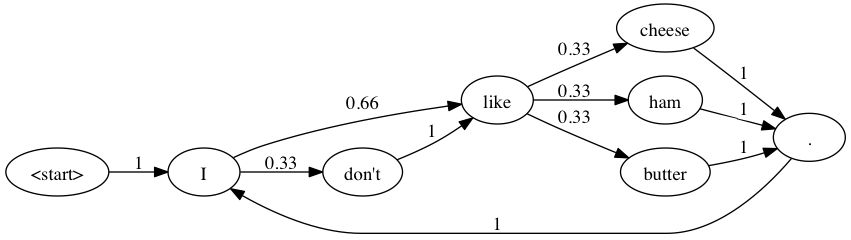
Each node in the graph (the circles) represents a word. Each edge (the arrows) represents the probability of a transition from one node to another.
Notice that each individual pair of words in the new text can be found in the source text but wholly new sentences have been created. The most important thing to notice is that each individual adjacent pair of words in the new text is present in the source text. You may also observe that in both texts all sentences start with the letter ‘I’, or more accurately, all periods are followed by an ‘I’. You can also see that some sentences such as “I like butter.” are repeated verbatim, however some wholly original sentences like “I like ham” are present as well. This goes to what was mentioned earlier about Markov chains being based on the probability of one word following another.
Applied to a larger source text, we can see:
There were a king with a large jaw and a queen with a plain face, on the throne of England; there were a king with a large jaw and a queen with a fair face, on the throne of France.
Transformed into:
There were a queen with a queen with a plain face, on the throne of England there were a plain face, on the throne of France. There were a large jaw and a plain face, on the throne of England there were a queen with a queen with a large jaw and a plain face, on the throne of France. There were a large jaw and a king with a queen with a king with a king with a large jaw and a large jaw and a king with a large jaw and a king with a king
It’s all in the order
All the preceding examples are Order-1. This means that each word generated is a function of the word preceding it. However, more readable text can be generated by increasing the number of words preceding it that must match. Making each word depend on the preceding 2 words would be Order-2. I went with an Order-1 generator for engulf for simplicity. If you’d like to see more examples of the different orders I recommend this excerpt from programming pearls.
How does this apply to HTTP load testing?
There is no one right way to load test a site. Any given test will give you a new piece of information, but it will never be a fully complete piece of information. What Markov chain generation does is give a nice mix between two different ways of generating load, combining the fuzzing of random request generation with the feel of replaying logs. I think of it as a happy medium.
Markov chains as a DSL
Once you know the rules of Markov chains you can craft a source text that will generate the pattern you want. For instance let’s say I want to simulate a session wherein a user accesses one page then retrieves two associated images, then accesses a second page and retrieves those two images again, plus a third new image. The following corpus might be useful:
http://localhost/index.html
http://localhost/header.jpg
http://localhost/logo.jpg
http://localhost/about.html
http://localhost/header.jpg
http://localhost/logo.jpg
http://localhost/sidebar.jpg
Given that source text we will see a variety of patterns similar to the original but with some new variations added in. One such possible variation might be:
http://localhost/index.html
http://localhost/header.jpg
http://localhost/logo.jpg
http://localhost/sidebar.jpg
Are Markov chains better than the alternatives?
No. Markov chains are another tool in the box. Whether they are right for testing your application is a decision you must make. One of the reasons I went with Markov chains in engulf is that it covers a lot different bases. They present a concise DSL for request pattern generation, and they are very efficient to transmit over the network versus a large chunk of an nginx or apache log file. They can almost be viewed as a very lossy form of text compression.
Implementing the chain in clojure
The clojure implementation I wrote for engulf (which needs a bit of cleanup for the record), will scan a source text, build the tree, and then return a lazy sequence of new words. The code first builds a dictionary of ‘requests’. Each request node in the graph has a TreeMap associated with it, with child nodes given a number between 0.0 and 1.0 according to their weight. In a case where node A’s probability is 0.66, B’s is 0.3, the map would key A as 0.66 and B as 1.0. A call to rand can be mapped directly onto this with a call to (.ceilingEntry ^NavigableMap mymap (rand)).
Trying it out
If you’d like to give Markov chain generation a spin, download a copy of my open source load tester engulf and give it a spin!